Unlocking the Power of Language: A Beginner’s Guide to Natural Language Processing (NLP) Fundamentals
In an increasingly digital world, the ability for computers to understand, interpret, and generate human language is no longer a futuristic dream but a present-day reality. From the smart assistant on your phone to the spam filter in your email, Natural Language Processing (NLP) is quietly revolutionizing how we interact with technology and extract insights from the vast ocean of text data around us.
If you’ve ever wondered how Google translates a webpage instantly, or how a chatbot answers your customer service queries, you’ve been exposed to the magic of NLP. This comprehensive guide will demystify Natural Language Processing, breaking down its core concepts and fundamental techniques in an easy-to-understand manner, perfect for beginners eager to explore this fascinating field.
What is Natural Language Processing (NLP)?
At its core, Natural Language Processing (NLP) is a branch of Artificial Intelligence (AI) and Machine Learning (ML) that focuses on enabling computers to understand, interpret, and generate human language in a valuable way.
Think of it this way:
- Human Language (Natural Language): This is the way we speak, write, and communicate with each other – filled with nuances, slang, context, and sometimes, ambiguity.
- Computer Language: This is the precise, logical, and structured language of programming code and data that computers understand.
NLP acts as the bridge between these two worlds. Its primary goal is to close the gap, allowing computers to process and make sense of the unstructured, complex nature of human language, just as humans do.
In essence, NLP teaches computers to "read," "understand," and "speak" like us.
Why is NLP So Important in Today’s World?
The sheer volume of text data generated daily is staggering – emails, social media posts, news articles, scientific papers, customer reviews, voice notes, and more. Without NLP, this data would remain largely inaccessible and incomprehensible to machines, making it difficult to extract valuable insights or automate language-based tasks.
NLP’s importance stems from its ability to:
- Automate Tedious Tasks: From summarizing long documents to routing customer emails, NLP can handle tasks that would otherwise require significant human effort.
- Extract Insights from Data: Businesses can analyze customer feedback at scale, identify market trends, or monitor brand sentiment by processing text data.
- Improve User Experience: Think of intelligent search engines, personalized recommendations, and seamless communication across language barriers.
- Enhance Accessibility: Speech-to-text and text-to-speech technologies make information more accessible for individuals with disabilities.
- Power Intelligent Systems: Chatbots, virtual assistants, and smart home devices rely heavily on NLP to understand and respond to user commands.
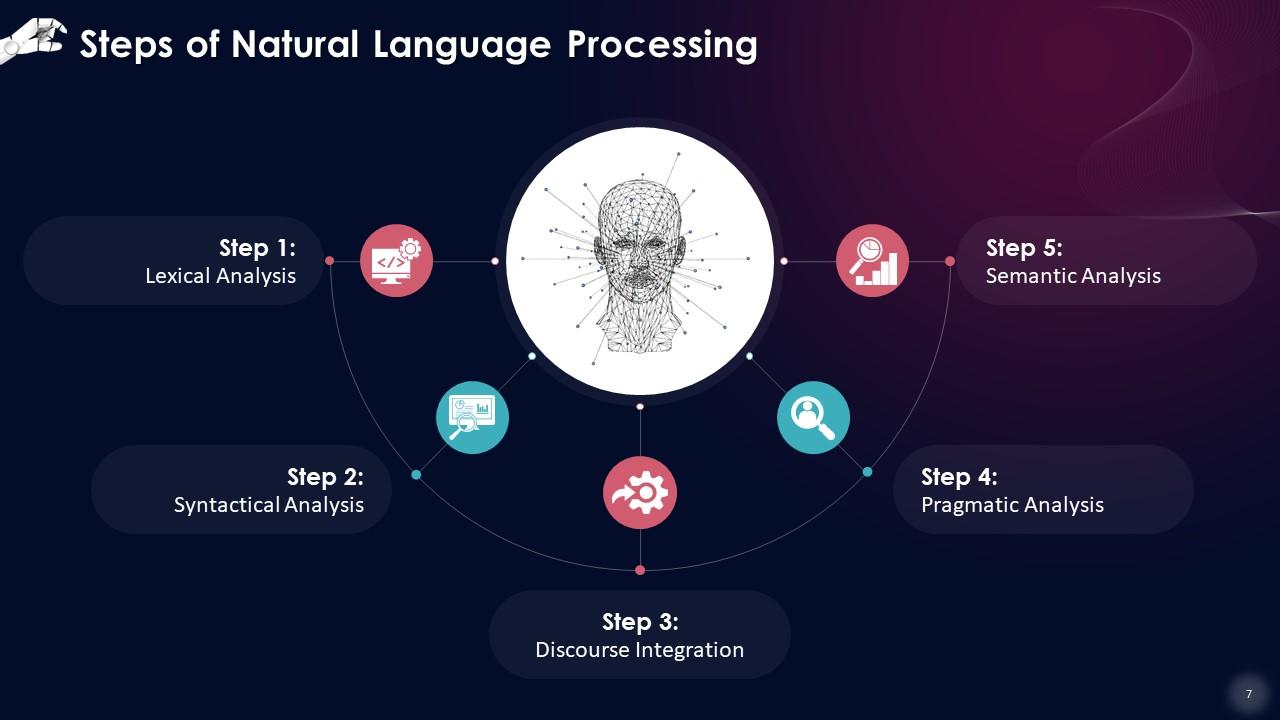
The NLP Pipeline: How Computers "Understand" Language (Simplified)
For a computer to understand human language, it doesn’t just "get it" instantly. Instead, it goes through a series of structured steps, often referred to as the NLP Pipeline. Imagine it like an assembly line where raw text is gradually refined and processed into something meaningful for the computer.
Here’s a simplified breakdown of the fundamental steps:
-
Text Collection & Pre-processing:
- Goal: Clean and prepare the raw text data so it’s ready for analysis. Human language is messy, and computers need it to be consistent.
- Steps involved:
- Gathering Data: Collecting text from various sources (web pages, documents, social media).
- Cleaning: Removing unwanted characters (e.g., HTML tags, special symbols), correcting typos, handling inconsistent formatting.
- Lowercasing: Converting all text to lowercase to treat "The" and "the" as the same word.
-
Tokenization:
- Goal: Break down the text into smaller, meaningful units.
- Process: Splitting sentences into individual words (word tokenization) or paragraphs into sentences (sentence tokenization). These individual units are called "tokens."
- Example: "Hello, world!" becomes ["Hello", ",", "world", "!"]
-
Removing Stop Words:
- Goal: Eliminate common, less meaningful words that don’t add much value to the overall understanding.
- Process: Removing words like "a," "an," "the," "is," "are," "and," etc. These words are common but often don’t carry significant semantic meaning.
- Example: "The quick brown fox jumps over the lazy dog." becomes "quick brown fox jumps lazy dog."
-
Stemming & Lemmatization:
- Goal: Reduce words to their root or base form to ensure different forms of a word are treated as the same.
- Stemming: A cruder process that chops off suffixes to get to a "stem." The stem might not be a real word.
- Example: "running," "runs," "ran" might all become "run." "beautiful," "beauty" might become "beauti."
- Lemmatization: A more sophisticated process that uses vocabulary and morphological analysis to return the dictionary form of a word (the "lemma"). The lemma is always a real word.
- Example: "running," "runs," "ran" all become "run." "better" becomes "good."
-
Part-of-Speech (POS) Tagging:
- Goal: Identify the grammatical role of each word in a sentence.
- Process: Labeling words as nouns (NN), verbs (VB), adjectives (JJ), adverbs (RB), etc. This helps understand sentence structure.
- Example: "The (DT) cat (NN) sat (VBD) on (IN) the (DT) mat (NN)."
-
Named Entity Recognition (NER):
- Goal: Identify and classify named entities in the text into pre-defined categories.
- Process: Recognizing names of people, organizations, locations, dates, monetary values, etc.
- Example: "Apple (ORG) is headquartered in Cupertino (LOC)."
-
Feature Extraction & Representation:
- Goal: Convert the processed text into numerical features that machine learning models can understand. Computers don’t "understand" words directly; they understand numbers.
- Methods:
- Bag-of-Words (BoW): Creates a vocabulary of all unique words and counts their occurrences in each document.
- TF-IDF (Term Frequency-Inverse Document Frequency): Weights words based on how frequently they appear in a document relative to how frequently they appear across all documents. This helps identify important words.
- Word Embeddings (e.g., Word2Vec, GloVe): Represent words as dense vectors (lists of numbers) in a multi-dimensional space, where words with similar meanings are located closer together. This captures semantic relationships.
-
Applying Machine Learning Models:
- Goal: Use the numerical representations of text to train models for specific NLP tasks.
- Process: Feeding the "features" into various machine learning algorithms (e.g., Naive Bayes, Support Vector Machines, Neural Networks, Deep Learning models like Transformers) to perform tasks like classification, prediction, or generation.
Key Concepts and Techniques in NLP (Deeper Dive)
Let’s elaborate on some of the fundamental techniques mentioned in the pipeline:
-
Tokenization:
- Why it matters: It’s the first step to breaking down unstructured text. Without it, the computer sees a blob of characters, not individual words or sentences.
- Challenges: Punctuation ("don’t" vs. "do n’t"), hyphenated words ("state-of-the-art"), emojis.
-
Stop Word Removal:
- Why it matters: Reduces noise and dimensionality (fewer words to process), focusing on the more significant terms.
- Consideration: Sometimes stop words are important for context (e.g., in sentiment analysis, "not good" vs. "good").
-
Stemming vs. Lemmatization:
- Stemming (e.g., Porter Stemmer): Faster and simpler. Good for information retrieval where approximate matches are fine.
- Lemmatization (e.g., WordNet Lemmatizer): Slower but more accurate, producing real words. Better for tasks requiring precise understanding like machine translation.
-
Part-of-Speech (POS) Tagging:
- Why it matters: Crucial for understanding the grammatical structure and meaning of a sentence. Helps resolve ambiguity (e.g., "book" as a noun vs. "book" as a verb).
-
Named Entity Recognition (NER):
- Why it matters: Essential for information extraction, building knowledge graphs, and answering specific questions from text. Imagine trying to find all company names in a news archive.
-
Sentiment Analysis:
- Why it matters: Determines the emotional tone behind a piece of text (positive, negative, neutral). Invaluable for businesses to gauge public opinion, customer satisfaction, or brand reputation.
- How it works: Often involves classifying text based on a trained model that recognizes words and phrases associated with different sentiments.
-
Word Embeddings (Vector Representations):
- Why it matters: This is a game-changer. Instead of just counting words, embeddings capture the meaning of words based on their context. Words like "king" and "queen" will be close together in the vector space, and the relationship "king – man + woman" might even equal "queen."
- Impact: Enables models to understand synonyms, analogies, and semantic relationships, leading to much more sophisticated NLP applications.
Common NLP Applications in the Real World
NLP isn’t just an academic concept; it’s integrated into countless tools and services we use daily:
- Chatbots and Virtual Assistants (Siri, Alexa, Google Assistant): Understand spoken or typed commands, answer questions, and perform tasks.
- Machine Translation (Google Translate, DeepL): Converts text or speech from one language to another while trying to preserve meaning and context.
- Spam Detection: Analyzes email content to identify and filter out unwanted messages based on patterns of spammy language.
- Text Summarization: Automatically condenses long documents into shorter, coherent summaries, saving time and highlighting key information.
- Sentiment Analysis (Customer Feedback Analysis): Businesses use this to analyze social media posts, reviews, and survey responses to understand customer feelings about products or services.
- Speech Recognition (Voice-to-Text): Converts spoken language into written text (e.g., dictation software, voice commands).
- Information Extraction: Automatically pulls specific pieces of information (e.g., names, dates, addresses) from unstructured text.
- Predictive Text and Autocorrect: Suggests words and corrects spelling/grammar errors as you type.
Challenges in Natural Language Processing
Despite incredible advancements, NLP still faces significant hurdles due to the inherent complexity of human language:
- Ambiguity: Words and sentences can have multiple meanings depending on context.
- Lexical Ambiguity: "Bank" (river bank vs. financial institution).
- Syntactic Ambiguity: "I saw the man with the telescope." (Who has the telescope?)
- Sarcasm, Irony, and Figurative Language: These are incredibly difficult for machines to detect as they often involve saying the opposite of what is meant or using non-literal expressions.
- Contextual Understanding: Machines struggle to understand the deeper meaning that relies on background knowledge, cultural nuances, or previous conversation turns.
- New Words and Slang: Language is constantly evolving. New words, slang, and internet jargon emerge rapidly, making it hard for models to keep up.
- Data Scarcity: For less common languages or very specific domains, there might not be enough labeled data to train robust NLP models.
- Noise in Data: Typos, grammatical errors, and informal language (especially in social media) can confuse models.
The Future of NLP: Towards More Human-like Understanding
The field of NLP is rapidly evolving, driven by breakthroughs in Deep Learning and the emergence of incredibly powerful Large Language Models (LLMs) like GPT-3, GPT-4, and others.
The future promises:
- More Contextual Understanding: LLMs are getting better at grasping long-range dependencies and complex conversational contexts.
- Improved Language Generation: More natural, coherent, and creative text generation, leading to advanced content creation, story writing, and even code generation.
- Multimodal NLP: Integrating language with other data types like images, video, and audio to create more holistic AI systems that can "see," "hear," and "understand" concurrently.
- Personalized AI: Highly customized NLP applications that adapt to individual user preferences, writing styles, and unique conversational patterns.
- Ethical Considerations: Increased focus on addressing biases in training data, ensuring fairness, privacy, and transparency in NLP models.
Getting Started with NLP for Beginners
Intrigued? The good news is that getting started with NLP is more accessible than ever!
- Learn Python: Python is the de facto language for NLP due to its rich ecosystem of libraries.
- Explore Key Libraries:
- NLTK (Natural Language Toolkit): A classic and comprehensive library for foundational NLP tasks (tokenization, stemming, POS tagging). Great for learning the basics.
- SpaCy: Faster and more production-ready, offering pre-trained models for various languages, perfect for building real-world applications.
- Hugging Face Transformers: The go-to library for working with state-of-the-art transformer models (like BERT, GPT) and pre-trained models for a vast array of NLP tasks.
- Online Courses and Tutorials: Websites like Coursera, edX, freeCodeCamp, and countless YouTube channels offer excellent beginner-friendly courses.
- Practice with Small Projects: Start with simple tasks like counting words, building a basic sentiment analyzer, or creating a simple chatbot.
Conclusion
Natural Language Processing is a fascinating and rapidly growing field that continues to bridge the gap between human communication and machine intelligence. By understanding the fundamental concepts – from cleaning text and breaking it into tokens to recognizing named entities and extracting sentiment – you’ve taken the first crucial step into this exciting domain.
The ability to process and understand human language is not just a technological feat; it’s a pathway to unlocking unprecedented insights, automating complex tasks, and creating more intuitive and intelligent systems that can truly understand and interact with the world as we do. As NLP continues to evolve, its impact on our daily lives will only grow, making it an incredibly valuable area to explore and master.
 Fundamentals")


Post Comment