Deep Learning Explained: How Neural Networks Learn and Transform Our World
Have you ever wondered how Netflix recommends movies you love, how your smartphone unlocks with your face, or how self-driving cars navigate complex roads? The answer, more often than not, lies in a revolutionary field of Artificial Intelligence called Deep Learning.
Deep Learning is not just a buzzword; it’s a powerful technology that’s rapidly reshaping industries and our daily lives. But what exactly is it, and how do these sophisticated systems, often referred to as Neural Networks, actually "learn"?
This comprehensive guide will demystify Deep Learning, breaking down its core concepts into easy-to-understand explanations. We’ll explore the fascinating process by which neural networks acquire knowledge, from their basic building blocks to the intricate algorithms that power their intelligence.
What is Deep Learning? A Subset of Machine Learning
Before diving into the "how," let’s clarify the "what."
Artificial Intelligence (AI) is the overarching concept of machines performing tasks that typically require human intelligence.
Machine Learning (ML) is a subset of AI that enables systems to learn from data without being explicitly programmed. Instead of writing rules for every possible scenario, you feed the machine data, and it learns patterns and makes predictions or decisions.
Deep Learning (DL) is a specialized subset of Machine Learning. What makes it "deep"? It uses Artificial Neural Networks with multiple layers (hence "deep") to learn increasingly complex representations of data. Think of it like a highly sophisticated filter with many stages, each refining its understanding of the input.
Key Characteristics of Deep Learning:
- Inspired by the Human Brain: While a simplified analogy, deep learning models are loosely inspired by the structure and function of the human brain’s neural connections.
- Layered Structure: They consist of multiple "hidden" layers between the input and output layers, allowing them to learn intricate patterns.
- Automatic Feature Extraction: Unlike traditional machine learning where you often have to manually tell the system what features to look for (e.g., "is this a cat? Look for whiskers and pointy ears"), deep learning models can learn these features on their own from raw data.
- Handles Large Datasets: Deep learning thrives on vast amounts of data, often outperforming other ML techniques when data is abundant.
The Building Blocks: Understanding Neural Networks
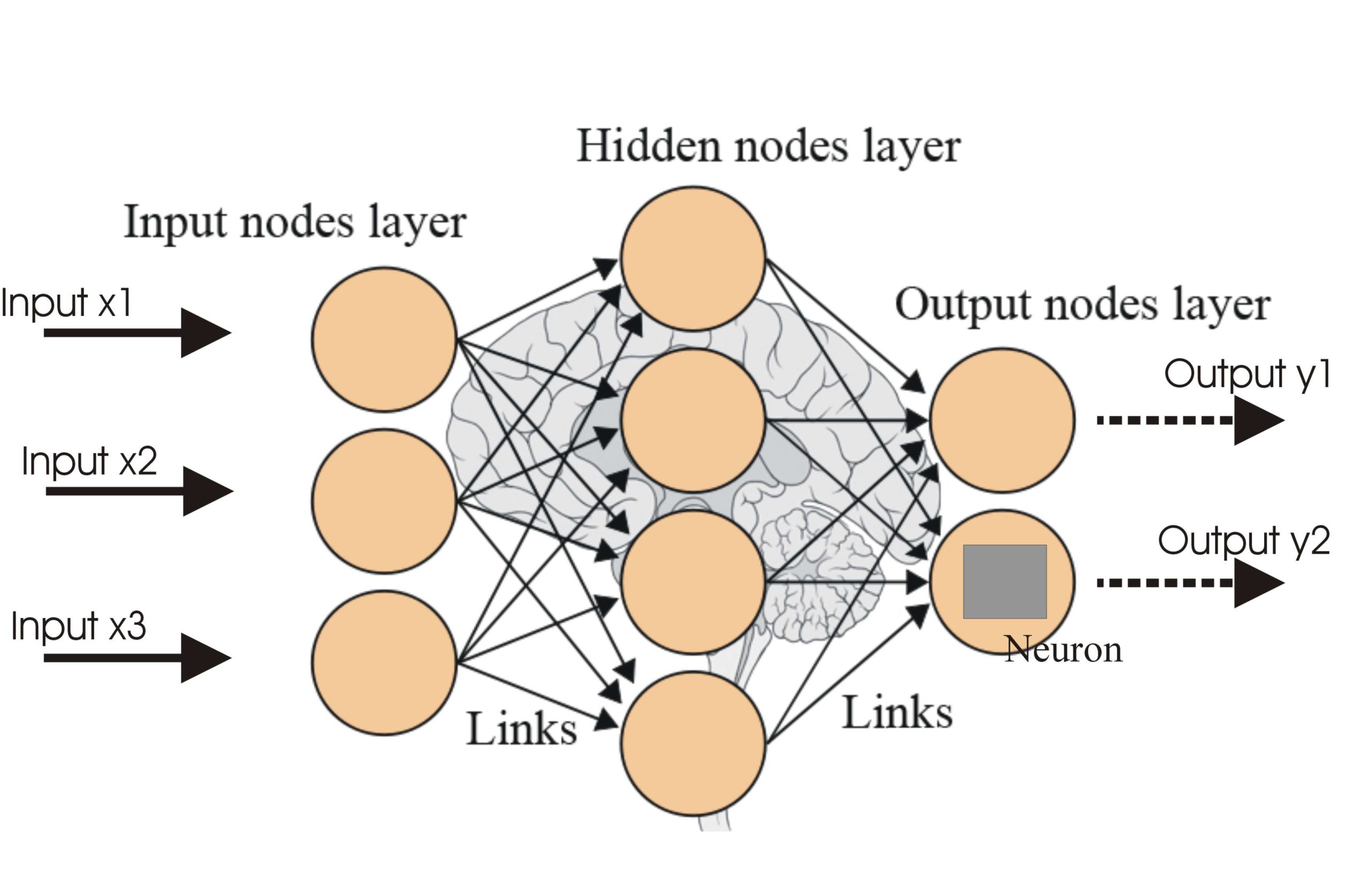
At the heart of Deep Learning lies the Artificial Neural Network (ANN). Imagine it as a network of interconnected "neurons" or "nodes," organized into layers.
1. Neurons (Nodes)
- What they are: The fundamental processing units of a neural network. Each neuron receives input, performs a simple computation, and then passes the result to other neurons.
- Analogy: Think of them as tiny decision-makers or information processors.
2. Connections and Weights
- What they are: Neurons are connected to each other, and each connection has an associated "weight."
- Weights: These are numerical values that determine the strength or importance of a connection. A higher weight means that input from that connection has a stronger influence on the receiving neuron.
- Analogy: If a neuron is a person, the connections are communication channels, and weights are how much attention that person pays to what’s said on each channel.
3. Layers
Neural networks are typically organized into three main types of layers:
- Input Layer:
- Purpose: Receives the raw data that the network needs to process.
- Example: If you’re classifying images of numbers, the input layer might receive the pixel values of an image. Each pixel could be a separate input neuron.
- Hidden Layers:
- Purpose: These are the "deep" layers where the magic happens. They perform complex computations, extracting increasingly abstract and meaningful features from the data.
- How they work: Each neuron in a hidden layer takes inputs from the previous layer, applies weights, sums them up, and then passes the result through an activation function. A deep network has multiple hidden layers.
- Analogy: If the input layer sees individual brushstrokes, the first hidden layer might recognize edges, the next might see shapes, and a deeper one might identify entire objects (like an eye or an ear in a face).
- Output Layer:
- Purpose: Produces the final result or prediction of the network.
- Example: For classifying numbers (0-9), the output layer might have 10 neurons, each representing a number. The neuron with the highest output value would be the network’s prediction.
4. Activation Functions
- What they are: A crucial component within each neuron (especially in hidden layers). After a neuron sums up its weighted inputs, this sum passes through an activation function.
- Purpose:
- Introduce Non-Linearity: Without activation functions, a neural network, no matter how many layers it has, would only be able to learn linear relationships. Real-world data is rarely linear. Activation functions allow the network to learn complex, non-linear patterns.
- Squash Output: They often squash the output of a neuron into a specific range (e.g., between 0 and 1, or -1 and 1), which can be useful for certain types of tasks.
- Common Examples:
- Sigmoid: Squashes values between 0 and 1, often used in output layers for binary classification.
- ReLU (Rectified Linear Unit): Outputs the input directly if it’s positive, otherwise it outputs zero. This is very popular in hidden layers due to its computational efficiency.
How Neural Networks Learn: The Training Process
Now for the core question: How do these interconnected neurons, with their weights and activation functions, actually "learn"? It’s an iterative process of trial and error, often compared to how a child learns by being corrected.
The learning process involves four primary steps, repeated over many cycles (called epochs) with vast amounts of data:
Step 1: Forward Propagation (Making a Guess)
This is the initial pass where information flows through the network from input to output.
- Input Data: You feed a piece of data (e.g., an image of the number "7") into the input layer.
- Weighted Sum: Each input neuron passes its value to the neurons in the first hidden layer. Each connection has a weight. The receiving neuron multiplies each input by its corresponding weight and sums them up.
- Activation: This sum then passes through the neuron’s activation function.
- Repeat: This process repeats layer by layer until the data reaches the output layer, where the network makes its initial prediction (e.g., it might guess the image is a "9" when it’s actually a "7").
- Analogy: Imagine throwing a dart at a target for the first time. You don’t know exactly how to aim, so your first throw is a guess.
Step 2: Calculating the Error (Knowing You’re Wrong)
After the network makes a prediction, it needs to know how "wrong" it was. This is where the Loss Function (also called Cost Function or Error Function) comes in.
-
Purpose: The loss function quantifies the difference between the network’s prediction and the actual correct answer (the "ground truth"). A higher loss value means a worse prediction.
-
Examples:
- Mean Squared Error (MSE): Commonly used for regression tasks (predicting continuous values).
- Cross-Entropy Loss: Often used for classification tasks.
-
Analogy: After throwing the dart, you measure how far it landed from the bullseye. This distance is your "error."
Step 3: Backpropagation (Learning from Mistakes)
This is arguably the most crucial and ingenious step in deep learning, enabling the network to learn efficiently.
- Error Distribution: The calculated error from the output layer is propagated backward through the network, layer by layer, all the way to the input layer.
- Weight Adjustment: As the error propagates backward, the network determines how much each individual weight in the network contributed to the overall error. It then adjusts these weights slightly to reduce the error.
- The "Gradient": Backpropagation essentially calculates the "gradient" of the loss function with respect to each weight. The gradient tells the network the direction and magnitude by which each weight needs to be changed to reduce the loss.
- Analogy: You missed the bullseye. Backpropagation is like analyzing your throw: "My arm was too far left, my wrist wasn’t strong enough." It tells you how to adjust your muscles (weights) to improve the next throw.
Step 4: Gradient Descent (Finding the Right Path)
Backpropagation provides the direction for adjustment, and Gradient Descent is the optimization algorithm that uses this information to actually update the weights.
- Minimizing Loss: The goal of Gradient Descent is to find the set of weights that minimizes the loss function. Imagine the loss function as a landscape with hills and valleys; the goal is to find the lowest valley.
- Taking Steps: Gradient Descent iteratively adjusts the weights by taking small steps in the direction opposite to the gradient (i.e., downhill).
- Learning Rate: This is a hyperparameter that controls the size of each step.
- Too large a learning rate: The network might overshoot the minimum loss, failing to converge or even diverging.
- Too small a learning rate: The network will learn very slowly and might get stuck in a local minimum.
- Analogy: You’re blindfolded on a hilly landscape and want to reach the lowest point. You feel the slope (gradient) around you and take a small step downhill. You repeat this until you can’t go any lower. The size of your steps is your "learning rate."
These four steps – Forward Propagation, Calculating Error, Backpropagation, and Gradient Descent – are repeated hundreds, thousands, or even millions of times across many data examples. With each iteration, the weights in the network are fine-tuned, and the network becomes progressively better at making accurate predictions.
Key Components of Deep Learning: A Summary
To consolidate our understanding, let’s recap the essential elements:
- Data: The fuel for deep learning. The more relevant and diverse, the better.
- Neurons (Nodes): The basic computational units.
- Layers: Organize neurons into input, hidden, and output stages.
- Weights & Biases: The parameters that the network learns. Weights determine the strength of connections, while biases act as an offset that allows the activation function to be shifted. Together, they represent the "knowledge" stored in the network.
- Activation Functions: Introduce non-linearity, allowing the network to learn complex patterns.
- Loss Function: Quantifies the error between prediction and actual value.
- Optimizer (e.g., Gradient Descent with Backpropagation): The algorithm that adjusts the weights and biases to minimize the loss.
- Epochs: One full pass of the entire training dataset through the neural network.
Why is Deep Learning So Powerful?
Deep Learning’s ability to automatically learn intricate patterns from raw data makes it incredibly powerful for tasks that are challenging for traditional programming or machine learning.
- Automatic Feature Learning: Deep networks can discover relevant features within data without human intervention. For example, in image recognition, they learn to identify edges, textures, and shapes on their own, rather than being told "look for eyes."
- Scalability with Data: As the amount of data increases, deep learning models often continue to improve in performance, whereas traditional algorithms might plateau.
- Handling Complex Data: They excel at processing unstructured data like images, audio, and text, which are difficult for rule-based systems.
- State-of-the-Art Performance: Deep learning has achieved groundbreaking results in fields like:
- Computer Vision: Facial recognition, object detection, medical image analysis.
- Natural Language Processing (NLP): Language translation, sentiment analysis, chatbots (like the one you’re interacting with!).
- Speech Recognition: Voice assistants (Siri, Alexa, Google Assistant).
- Recommendation Systems: Personalizing content on Netflix, Amazon, Spotify.
- Autonomous Systems: Self-driving cars, robotics.
- Drug Discovery & Healthcare: Identifying patterns in medical data, accelerating research.
The Future of Deep Learning
Deep Learning is still a rapidly evolving field. Researchers are constantly developing new architectures, training techniques, and applications. As computational power continues to grow and more data becomes available, the capabilities of deep learning are only expected to expand.
However, it’s also important to acknowledge the challenges, such as the need for vast amounts of data, computational resources, and addressing ethical concerns related to bias and transparency in AI systems.
Conclusion: Unlocking the Intelligence Within Data
Deep Learning, powered by sophisticated Neural Networks, represents a monumental leap in Artificial Intelligence. By mimicking, in a highly simplified way, the learning process of the human brain, these systems can identify complex patterns, make predictions, and drive innovation across virtually every sector.
From understanding how a neuron processes information to grasping the iterative dance of forward propagation, backpropagation, and gradient descent, you now have a foundational understanding of how these powerful models learn. It’s a field that continues to push the boundaries of what machines can achieve, promising an even more intelligent and automated future.
The journey into Deep Learning is fascinating and rewarding. As you continue to explore, you’ll discover the immense potential of these "thinking" machines to solve some of humanity’s most complex challenges.
Frequently Asked Questions (FAQs) about Deep Learning
Q1: What’s the main difference between AI, Machine Learning, and Deep Learning?
A1: AI is the broad concept of machines exhibiting intelligence. Machine Learning is a subset of AI where machines learn from data without explicit programming. Deep Learning is a further subset of Machine Learning that uses multi-layered neural networks to learn complex patterns, often from unstructured data.
Q2: Why is it called "Deep" Learning?
A2: It’s called "deep" because of the multiple "hidden" layers in its neural network architecture. Traditional neural networks might have one or two hidden layers, while deep networks can have tens, hundreds, or even thousands of layers, allowing them to learn highly abstract and hierarchical representations of data.
Q3: Do Deep Learning models truly "think" like humans?
A3: No, not in the sense of consciousness or genuine understanding. Deep Learning models are highly sophisticated pattern recognition machines. They excel at specific tasks by finding statistical relationships in data, but they don’t possess common sense, emotional intelligence, or the ability to generalize knowledge in the same way humans do.
Q4: What is a "learning rate" in Deep Learning?
A4: The learning rate is a hyperparameter that controls how much the weights of the network are adjusted with respect to the loss gradient during training. It determines the step size taken during gradient descent. A well-tuned learning rate is crucial for efficient and effective training.
Q5: How long does it take to train a Deep Learning model?
A5: Training time varies wildly depending on the model’s complexity (number of layers and neurons), the size and nature of the dataset, and the computational resources available (e.g., CPU vs. GPU vs. specialized AI chips). It can range from minutes for simple models to days or even weeks for state-of-the-art models on massive datasets.
Q6: What are some real-world applications of Deep Learning?
A6: Deep Learning powers many technologies we use daily: facial recognition in phones, voice assistants (Siri, Alexa), recommendation engines (Netflix, Amazon), medical image analysis, natural language translation, fraud detection, self-driving cars, and much more.



Post Comment