Mastering Disaster Recovery Strategies: Your Beginner’s Guide to Protecting Your Business
In today’s fast-paced digital world, businesses of all sizes rely heavily on their IT systems and data to operate. But what happens when the unexpected strikes? A power outage, a cyberattack, a natural disaster, or even a simple human error can bring your operations to a grinding halt, leading to lost revenue, damaged reputation, and even business failure.
This is where Disaster Recovery (DR) comes in. Think of it as your business’s superhero cape, ready to swoop in and minimize damage when disaster strikes. It’s not just about getting back online; it’s about getting back online quickly and efficiently, with as little data loss as possible.
This comprehensive guide will demystify Disaster Recovery Strategies, breaking down complex concepts into easy-to-understand language. Whether you’re a small startup or a growing enterprise, understanding these strategies is crucial for building a resilient and future-proof business.
What Exactly is Disaster Recovery? (And Why You Absolutely Need It)
At its core, Disaster Recovery (DR) is a set of policies, tools, and procedures that enable an organization to resume or continue critical operations after a disruptive event. It’s about planning for the worst-case scenario so you can bounce back.
Why is it so vital?
- Minimizes Downtime: Every minute your systems are down can cost your business money, opportunities, and customer trust. DR aims to reduce this downtime significantly.
- Prevents Data Loss: Your data is your business’s lifeblood. DR strategies focus on protecting this invaluable asset, ensuring minimal or no data loss.
- Protects Reputation and Customer Trust: Customers expect reliability. A swift recovery demonstrates competence and builds confidence.
- Ensures Business Continuity: While often used interchangeably, DR is a part of Business Continuity (BC). BC is the broader plan to keep the business running during and after a disaster, while DR specifically focuses on the technological recovery.
- Meets Regulatory Compliance: Many industries have strict regulations regarding data protection and uptime, making a robust DR plan a legal necessity.
- Saves Money in the Long Run: The cost of proactive DR planning is almost always less than the cost of reacting to a disaster without a plan.
Key Concepts You Need to Understand
Before diving into specific strategies, let’s clarify some fundamental terms you’ll encounter in the world of Disaster Recovery:
-
Recovery Point Objective (RPO):
- What it means: This is the maximum amount of data (measured in time) that your business can afford to lose following a disaster.
- Example: An RPO of 1 hour means you can’t lose more than 1 hour’s worth of data. If your last backup was 5 minutes ago, and your RPO is 1 hour, you’re good! If your last backup was 2 hours ago, you’ve exceeded your RPO.
- Think of it as: "How far back in time can we go with our data before it becomes a major problem?"
-
Recovery Time Objective (RTO):
- What it means: This is the maximum amount of time your business can afford to be down after a disaster before critical operations are restored.
- Example: An RTO of 4 hours means your key systems must be back up and running within 4 hours of an incident.
- Think of it as: "How long can we afford for our systems to be offline?"
-
Disaster Recovery Plan (DRP):
- What it means: This is the comprehensive, documented roadmap that outlines the procedures, roles, and responsibilities for recovering your IT systems and data after a disaster. It’s your "playbook" for recovery.
-
Failover:
- What it means: The process of automatically or manually switching from a primary system or data center to a secondary, standby system or data center when the primary one fails.
- Think of it as: A backup generator kicking in when the main power goes out.
The Pillars of an Effective Disaster Recovery Strategy
Regardless of the specific strategies you choose, a strong DR plan rests on these foundational pillars:
-
Robust Data Backup:
- This is your first line of defense. It involves making copies of your important data and storing them securely.
- Types of Backups:
- Full Backup: Copies all selected data. Slowest to perform, but fastest to restore.
- Incremental Backup: Copies only the data that has changed since the last backup (of any type). Fastest to perform, but slowest to restore.
- Differential Backup: Copies only the data that has changed since the last full backup. Faster to perform than full, faster to restore than incremental.
- The 3-2-1 Rule: A widely recommended best practice:
- 3 copies of your data (the original + two backups).
- 2 different media types (e.g., internal hard drive and cloud storage).
- 1 offsite copy (stored in a different physical location, away from the original).
-
Data Replication:
- While backups capture data at specific points in time, replication creates a near real-time copy of your data or entire systems.
- Synchronous Replication: Data is written simultaneously to both the primary and secondary locations. Ensures zero data loss (RPO near zero) but requires high-speed connections and can impact performance over long distances.
- Asynchronous Replication: Data is written to the primary location first, then copied to the secondary. Allows for greater distances and less performance impact but has a small RPO (some data loss possible).
-
Recovery Sites:
- These are alternative locations where your IT operations can resume after a disaster at your primary site.
- Hot Site: A fully equipped, ready-to-go data center with hardware, software, and data mirroring the primary site. Offers the fastest recovery (low RTO) but is the most expensive.
- Warm Site: A partially equipped site with necessary hardware, but you might need to load your data and software. Slower recovery than a hot site, less expensive.
- Cold Site: A basic facility with power and cooling, but no hardware or data. You’d need to bring in everything. Cheapest option, but slowest recovery (high RTO).
-
Regular Testing and Maintenance:
- A DR plan is useless if it hasn’t been tested. Regular testing ensures that your strategies work as expected and identifies any gaps or issues.
- Types of Tests:
- Tabletop Exercises: A discussion-based test where the team walks through the plan.
- Simulated Failovers: Actually switching to backup systems to ensure they work.
- Full Drills: A complete simulation of a disaster, including recovery.
-
Clear Communication Plan:
- During a disaster, knowing who to contact, how, and what to say is critical. This includes internal teams, employees, customers, vendors, and even media (if necessary).
Common Disaster Recovery Strategies Explained
Now, let’s explore the most common approaches businesses take for their DR needs:
1. On-Premise Disaster Recovery
- How it works: You build and manage your own secondary data center or recovery site. All hardware, software, and infrastructure are owned and maintained by your organization.
- Pros:
- Full Control: You have complete control over your data, hardware, and security.
- Potentially Faster for High RTO/RPO Needs (if built correctly): For very specific, extremely low RTO/RPO requirements, a dedicated on-premise setup can be optimized.
- Cons:
- High Upfront Cost: Significant investment in hardware, software, real estate, and power.
- High Ongoing Maintenance: Requires dedicated IT staff, regular upgrades, and significant operational expenses.
- Scalability Challenges: Difficult and costly to scale up or down as your needs change.
- Geographic Risk: If your primary and secondary sites are too close, they could both be affected by a regional disaster (e.g., a power grid failure).
2. Cloud-Based Disaster Recovery (DRaaS)
- How it works: You leverage the power of cloud computing to host your DR environment. A third-party provider (like Amazon Web Services, Microsoft Azure, Google Cloud, or a specialized DRaaS vendor) manages the infrastructure, and you pay for the resources you use.
- DRaaS (Disaster Recovery as a Service): This is a specific offering where the vendor manages the entire DR process for you, including replication, failover, and recovery, often with guaranteed RPO/RTOs.
- Pros:
- Cost-Effective: Eliminates the need for expensive hardware and dedicated recovery sites. You pay for what you use.
- Scalability & Flexibility: Easily scale resources up or down based on demand or recovery needs.
- Geographic Diversity: Cloud providers have data centers worldwide, allowing you to choose locations far from your primary site.
- Faster Deployment: Can be set up much quicker than building an on-premise solution.
- Managed Services: DRaaS providers offer expertise and handle much of the technical heavy lifting.
- Improved RPO/RTO: Cloud replication capabilities often allow for very aggressive RPO/RTO targets.
- Cons:
- Reliance on Internet Connection: Recovery depends on stable, high-bandwidth internet.
- Security Concerns (Perception vs. Reality): While cloud providers invest heavily in security, some businesses have concerns about data in a third-party environment.
- Vendor Lock-in: Switching providers can be complex.
- Potential for Unexpected Costs: If not managed carefully, cloud usage can lead to higher-than-expected bills.
3. Hybrid Disaster Recovery
- How it works: This strategy combines elements of both on-premise and cloud-based DR. For example, critical applications and very sensitive data might be replicated to a dedicated on-premise recovery site, while less critical systems or archived data are backed up or replicated to the cloud.
- Pros:
- Best of Both Worlds: Balances control with scalability and cost-effectiveness.
- Optimized Resource Allocation: Allows you to tailor DR solutions to specific applications’ needs and criticality.
- Flexibility: Provides more options for different types of disasters or recovery scenarios.
- Cons:
- Increased Complexity: Managing both on-premise and cloud environments adds complexity to your DR plan.
- Integration Challenges: Ensuring seamless operation between the two environments can be tricky.
4. Virtualization-Based Disaster Recovery
- How it works: This strategy leverages virtualization technology (like VMware or Hyper-V) to create virtual copies of your servers and applications. These virtual machines (VMs) can then be easily replicated to a recovery site (on-premise or cloud) and spun up quickly in the event of a disaster.
- Pros:
- Portability: VMs are highly portable, making it easy to move them between physical servers or to cloud environments.
- Faster Recovery: Spinning up a VM is generally much quicker than rebuilding a physical server.
- Cost-Effective: Reduces hardware needs by consolidating multiple servers onto fewer physical machines.
- Simplified Testing: Testing DR is easier with VMs as you can create isolated test environments.
- Cons:
- Initial Setup: Requires an initial investment in virtualization software and expertise.
- Performance Overhead: While minimal, virtualization can introduce a slight performance overhead.
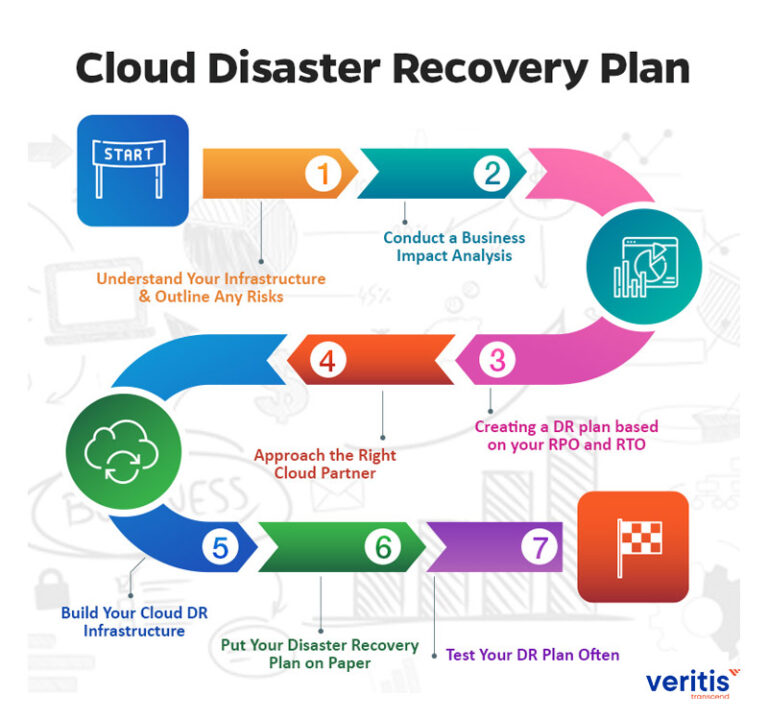
Building Your Disaster Recovery Plan: A Step-by-Step Guide
Creating a robust DR plan might seem daunting, but breaking it down into manageable steps makes it achievable.
-
Assess Your Risks:
- What are the most likely threats to your business? (e.g., power outages, cyberattacks, natural disasters specific to your region, hardware failure, human error).
- How would each threat impact your operations?
-
Identify Critical Assets & Processes:
- What data, applications, servers, and networks are absolutely essential for your business to function?
- What are your core business processes that must continue? (e.g., sales, customer support, payroll).
-
Define Your RPO & RTO:
- For each critical asset and process, determine its acceptable RPO (how much data can you lose?) and RTO (how long can you be down?). This will guide your strategy choices.
- Example: For customer transaction data, your RPO might be minutes, and RTO hours. For archived internal documents, your RPO might be days, and RTO weeks.
-
Choose Your Strategies & Technologies:
- Based on your RPO/RTO, budget, and resources, decide which DR strategies (on-premise, cloud, hybrid, virtualization) and specific technologies (backup software, replication tools, DRaaS provider) are best suited.
-
Document Your Plan:
- This is your DR playbook. It should be clear, concise, and accessible to everyone involved.
- Include:
- Emergency contact lists (internal and external).
- Roles and responsibilities for each team member during a disaster.
- Step-by-step recovery procedures for each critical system.
- Location of backup data and recovery sites.
- Communication protocols (who to notify, how, and what to say).
- Testing schedules and results.
-
Train Your Team:
- Ensure all relevant employees understand their roles and responsibilities in the DR plan. Conduct regular training sessions.
-
Test, Test, Test!
- This cannot be stressed enough. Conduct regular drills and simulations to validate your plan’s effectiveness. Adjust the plan based on test results.
- Tip: Don’t just test the tech; test the people and the process.
-
Review and Update Regularly:
- Your business changes, your technology changes, and threats evolve. Review your DR plan at least annually, or whenever there are significant changes to your IT infrastructure or business operations.
Tips for a Successful Disaster Recovery Strategy
- Start Simple: Don’t try to solve everything at once. Focus on your most critical systems first.
- Automate Where Possible: Automation reduces human error and speeds up recovery processes.
- Don’t Forget Non-IT Aspects: DR isn’t just about technology. Consider physical facilities, supply chains, and employee welfare.
- Budget Accordingly: Allocate sufficient resources for both initial setup and ongoing maintenance/testing.
- Consider a DRaaS Provider: Especially for small to medium-sized businesses, DRaaS can offer enterprise-level protection without the hefty upfront investment.
- Keep Offsite Copies: Always ensure at least one copy of your backup data is stored in a separate, secure physical location.
- Document Everything: Clear, up-to-date documentation is invaluable during a crisis.
- Learn from Every Test: Treat every DR test (even a small one) as an opportunity to improve.
Conclusion: Invest in Resilience, Not Just Recovery
Disaster recovery is no longer a luxury; it’s a fundamental requirement for any business operating in the digital age. By understanding the core concepts, exploring different strategies, and diligently building and testing your own Disaster Recovery Plan, you’re not just preparing for the worst – you’re investing in the long-term resilience, stability, and reputation of your business.
Don’t wait for a disaster to strike. Start planning your robust Disaster Recovery strategy today and ensure your business can weather any storm.


Post Comment